Code
download.file("https://github.com/profrichharris/profrichharris.github.io/raw/main/MandM/data/covid_extract.csv", "covid.csv", mode = "wb", quiet = TRUE) What Is the Tidyverse?
If base R is R Classic then tidyverse is a new flavour of R, designed for data science. It consists of a collection of R packages that “share an underlying design philosophy, grammar, and data structures.”
Tidyverse is easier to demonstrate than to pin-down to some basics so let’s work through an example using both base R and tidyverse to illustrate some differences.
If, as suggested in ‘Getting Started’, you have created an R Project to contain all the files you create and download for this course then open it now by using File –> Open Project… from the dropdown menus in R Studio. If you have not created one then now might be a good time!
We will begin by downloading a data file to use. It will be downloaded to your working directory, which is the folder associated with your R Project if you are using one. You can check the working directory by using getwd() and change it using Session –> Set Working Directory or with the function setwd(dir) where dir is the chosen directory. If you have created a Project then the working directory is that of the Project.
The data are an extract of the Covid Data Dashboard for England in December 2021. Some prior manipulation and adjustments to those data have been undertaken for another project so treat them as indicative only. The actual reported numbers may have been changed slightly from their originals although only marginally so.
download.file("https://github.com/profrichharris/profrichharris.github.io/raw/main/MandM/data/covid_extract.csv", "covid.csv", mode = "wb", quiet = TRUE) We also need to require(tidyverse) ready for use.
require(tidyverse)
If you get a warning message saying there is no package called tidyverse then you need to install it: install.packages("tidyverse", dependencies = TRUE). You will find that some people prefer to use library() instead of require(). The difference between them is subtle but you can find an argument in favour of using library() here even though I usually don’t.
Let’s read-in and take a look at the data. First in base R.
df1 <- read.csv("covid.csv")
head(df1) MSOA11CD regionName X2021.12.04 X2021.12.11 X2021.12.18 X2021.12.25 All.Ages
1 E02000002 London 25 48 148 176 7726
2 E02000003 London 46 58 165 215 11246
3 E02000004 London 24 44 100 141 6646
4 E02000005 London 58 97 185 231 10540
5 E02000007 London 38 94 153 205 10076
6 E02000008 London 54 101 232 245 12777Now using tidyverse,
df2 <- read_csv("covid.csv")
slice_head(df2, n = 6)# A tibble: 6 × 7
MSOA11CD regionName `2021-12-04` `2021-12-11` `2021-12-18` `2021-12-25`
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 E02000002 London 25 48 148 176
2 E02000003 London 46 58 165 215
3 E02000004 London 24 44 100 141
4 E02000005 London 58 97 185 231
5 E02000007 London 38 94 153 205
6 E02000008 London 54 101 232 245
# ℹ 1 more variable: `All Ages` <dbl>There are some similarities – for example the function read.csv reads-in a file of comma separated variables, as does read_csv. However, the output from these functions differ. First, tidyverse has, in this case, handled the names of the variables better. It has also created what is described as a tibble which is “a modern reimagining of the data.frame, keeping what time has proven to be effective, and throwing out what is not.” You can find out more about them and how they differ from traditional data frames here. Basically, they are a form of data frame that fit into tidyverse’s philosophy to try and keep ‘things’ tidy through a shared underlying design philosophy, grammar and data structures.
We will now: - select the regionName, 2021-12-04 and All Ages variables; - rename the second of these as cases and the third as population; - and look at the data again to check that it has worked.
In base R,
df1 <- df1[, c("regionName", "X2021.12.04", "All.Ages")]
names(df1)[2:3] <- c("cases", "population")
head(df1) regionName cases population
1 London 25 7726
2 London 46 11246
3 London 24 6646
4 London 58 10540
5 London 38 10076
6 London 54 12777In tidyverse,
df2 <- select(df2, regionName, `2021-12-04`, `All Ages`)
df2 <- rename(df2, cases = `2021-12-04`, population = `All Ages`)
slice_head(df2, n = 6)# A tibble: 6 × 3
regionName cases population
<chr> <dbl> <dbl>
1 London 25 7726
2 London 46 11246
3 London 24 6646
4 London 58 10540
5 London 38 10076
6 London 54 12777Comparing the two, the tidyverse code may be more intuitive to understand because of its use of verbs as functions: select(), rename() and so forth.
Now we shall bring the two previous stages together, using what is referred to as a pipe. Without worrying about the detail, which we will return to presently, here is an example of a pipe, |> being used in base R:
read.csv("covid.csv") |>
(\(x) x[, c("regionName", "X2021.12.04", "All.Ages")])() -> df1
names(df1)[2:3] <- c("cases", "population")
df1 |>
head() regionName cases population
1 London 25 7726
2 London 46 11246
3 London 24 6646
4 London 58 10540
5 London 38 10076
6 London 54 12777
The above will only work if you are using R version 4.1.0 or above. You can check which version you are running by using R.Version()$version.
Here is the same process using tidyverse and a different pipe, %>%,
read_csv("covid.csv") %>%
select(regionName, `2021-12-04`, `All Ages`) %>%
rename(cases = `2021-12-04`, population = `All Ages`) %>%
slice_head(n = 6)# A tibble: 6 × 3
regionName cases population
<chr> <dbl> <dbl>
1 London 25 7726
2 London 46 11246
3 London 24 6646
4 London 58 10540
5 London 38 10076
6 London 54 12777The obvious difference here is that the tidyverse code is more elegant. But what is the pipe and what is the difference between |> in the base R code and %>% in the tidyverse example?
A pipe is really just a way of sending (’piping`) something from one line of code to the next, to create a chain of commands (forgive the mixed metaphors). For example,
x <- 0:10
mean(x)[1] 5Could be calculated as
0:10 |>
mean()[1] 5As
0:10 %>%
mean()[1] 5or, if you want to save on a few characters of code,
0:10 %>%
mean[1] 5However, this won’t work:
0:10 |>
meanThis is confusing but it is because of the different pipes, one (|>) a more recent development than the other (%>%).
A more complicated example of piping is below. It employs the function sapply(), a variant of the function lapply(X, FUN) that takes a list X and applies the function FUN to each part of it. In the example, it is the function mean.
Here it is without any pipes:
x <- list(0:10, 10:20)
# Creates a list with two parts: the numbers 0 to 10, and 10 to 20
y <- sapply(x, mean)
# Calculates the mean for each part of the list, which are 5 and 15
sum(y)[1] 20 # Sums together the two means, giving 20With pipes, the above could instead be written as
list(0:10, 10:20) |>
sapply(mean) |>
sum()[1] 20or as
list(0:10, 10:20) %>%
sapply(mean) %>%
sum()[1] 20All three arrive at the same answer, which is 20.
So far, so good but what is the difference between |> and %>%? The answer is that %>% was developed before |> in the magrittr package, whereas |> is R’s new native pipe. They are often interchangeable but not always.
At the moment, the |> pipe is less flexible to use than %>%. Consider the following example. The final two lines of code work fine using %>% to pipe the data frame into the regression model, which is a line of best fit between the x and y values (the function lm() fits a linear model which can be used to predict a y value from a value of x).
1:100 %>%
data.frame(x = ., y = 2*. + rnorm(100)) %>%
lm(y ~ x, data = .) %>%
summary()
Call:
lm(formula = y ~ x, data = .)
Residuals:
Min 1Q Median 3Q Max
-2.82168 -0.82551 0.00308 0.85229 1.77659
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.129235 0.212120 -0.609 0.544
x 2.004212 0.003647 549.599 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.053 on 98 degrees of freedom
Multiple R-squared: 0.9997, Adjusted R-squared: 0.9997
F-statistic: 3.021e+05 on 1 and 98 DF, p-value: < 2.2e-16(note: the output you get will likely differ from mine because the function rnorm() adds some random variations to the data)
However, it does not work with the pipe, |> because it does not recognise the place holder . that we had previously used to represent what was flowing through the pipe.
# The following code does not work
1:100 |>
data.frame(x = ., y = 2*. + rnorm(100)) |>
lm(y ~ x, data = .) |>
summary()To solve the problem, the above code can be modified by wrapping the regression part in another function but the end result is rather ‘clunky’.
1:100 |>
(\(z) data.frame(x = z, y = 2*z + rnorm(100)))() |>
(\(z) lm(y ~ x, data = z))() |>
summary()
Call:
lm(formula = y ~ x, data = z)
Residuals:
Min 1Q Median 3Q Max
-2.8942 -0.7092 0.1085 0.7695 3.3349
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.027888 0.233310 -0.12 0.905
x 1.999735 0.004011 498.56 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.158 on 98 degrees of freedom
Multiple R-squared: 0.9996, Adjusted R-squared: 0.9996
F-statistic: 2.486e+05 on 1 and 98 DF, p-value: < 2.2e-16Over time, expect |> to be developed and to supersede %>%. For now, you are unlikely to encounter errors using %>% as a substitute for |> but you might using |> instead of %>%. In other words, %>% is the safer choice if you are unsure, although the |> should be faster but might not be:
install.packages("microbenchmark", dependencies = TRUE)
require("microbenchmark")
microbenchmark(
1:100 %>%
data.frame(x = ., y = 2*. + rnorm(100)) %>%
lm(y ~ x, data = .) %>%
summary(),
1:100 |>
(\(z) data.frame(x = z, y = 2*z + rnorm(100)))() |>
(\(z) lm(y ~ x, data = z))() |>
summary(),
times = 100
)Unit: microseconds
expr
1:100 %>% data.frame(x = ., y = 2 * . + rnorm(100)) %>% lm(y ~ x, data = .) %>% summary()
summary((function(z) lm(y ~ x, data = z))((function(z) data.frame(x = z, y = 2 * z + rnorm(100)))(1:100)))
min lq mean median uq max neval cld
1001.3 1051.0 1144.801 1086.95 1134.8 5120.7 100 a
976.3 1044.6 1107.619 1085.65 1118.6 1637.9 100 aAfter that digression into piping, let’s return to our example that is comparing base R and tidyverse to read-in a table of data, select variables, rename one and, in the following, to calculate the number of COVID-19 cases per English region as a percentage of their estimated populations in the week ending 2021-12-04.
First, in base R:
df1 <- read.csv("covid.csv")
df1 <- df1[, c("regionName", "X2021.12.04", "All.Ages")]
names(df1)[c(2,3)] <- c("cases", "population")
cases <- tapply(df1$cases, df1$regionName, sum) # Total cases per region
cases East Midlands East of England London
25472 35785 43060
North East North West South East
10796 31185 62807
South West West Midlands Yorkshire and The Humber
33846 26554 21079 # This step isn't necessary but is included
# to show the result of the line above
population <- tapply(df1$population, df1$regionName, sum)
# Total population per region
rate <- round(cases / population * 100, 3)
rate East Midlands East of England London
0.524 0.571 0.479
North East North West South East
0.403 0.423 0.681
South West West Midlands Yorkshire and The Humber
0.598 0.445 0.381 Now using tidyverse,
read_csv("covid.csv") |>
select(regionName, `2021-12-04`, `All Ages`) |>
rename(cases = `2021-12-04`, population = `All Ages`) |>
group_by(regionName) |>
summarise(across(where(is.numeric), sum)) |>
mutate(rate = round(cases / population * 100, 3)) |>
print(n = Inf)# A tibble: 9 × 4
regionName cases population rate
<chr> <dbl> <dbl> <dbl>
1 East Midlands 25472 4865583 0.524
2 East of England 35785 6269161 0.571
3 London 43060 8991550 0.479
4 North East 10796 2680763 0.403
5 North West 31185 7367456 0.423
6 South East 62807 9217265 0.681
7 South West 33846 5656917 0.598
8 West Midlands 26554 5961929 0.445
9 Yorkshire and The Humber 21079 5526350 0.381Either way produces the same answers but, again, there is an elegance and consistency to the tidyverse way of doing it (which works just fine with the |> pipe) that is, perhaps, missing from base R.
As a final step for the comparison, we will extend the code to visualise the regional COVID-19 rates in a histogram, with a rug plot included. A rug plot is a way of preserving the individual data values that would otherwise be ‘lost’ within the bins of a histogram.
As previously, we begin with base R,
df1 <- read.csv("covid.csv")
df1 <- df1[, c("regionName", "X2021.12.04", "All.Ages")]
names(df1)[c(2,3)] <- c("cases", "population")
cases <- tapply(df1$cases, df1$regionName, sum)
population <- tapply(df1$population, df1$regionName, sum)
rate <- round(cases / population * 100, 3)
hist(rate, xlab = "rate (cases as % of population)",
main = "Regional COVID-19 rates: week ending 2021-12-04")
rug(rate, lwd = 2)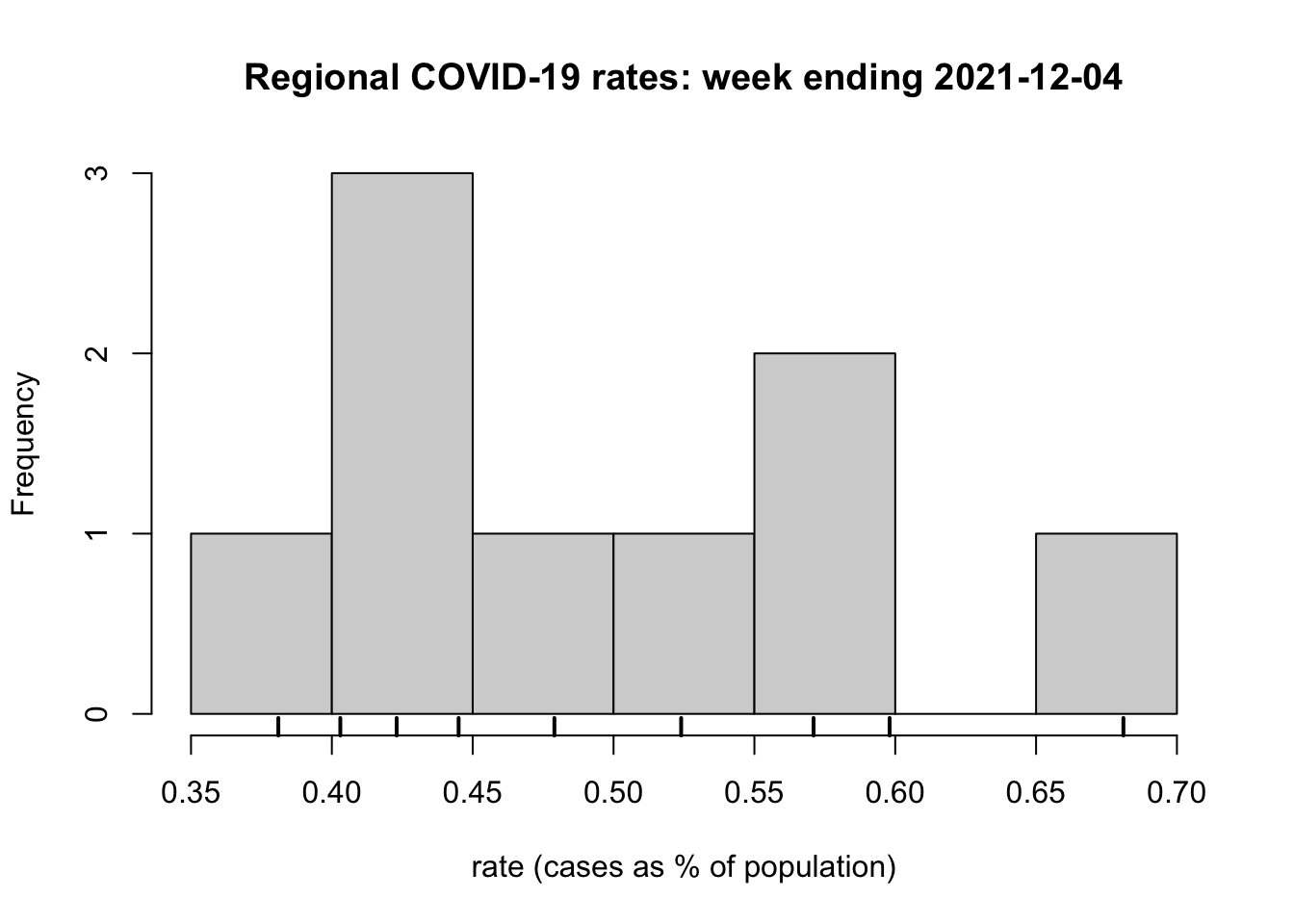
…and continue with tidyverse, creating the output in such a way that it mimics the previous plot.
require(ggplot2)
read_csv("covid.csv") |>
select(regionName, `2021-12-04`, `All Ages`) |>
rename(cases = `2021-12-04`, population = `All Ages`) |>
group_by(regionName) |>
summarise(across(where(is.numeric), sum)) |>
mutate(rate = round(cases / population * 100, 3)) -> df2
df2 |>
ggplot(aes(x = rate)) +
geom_histogram(colour = "black", fill = "grey", binwidth = 0.05,
center = -0.025) +
geom_rug(linewidth = 2) +
labs(x = "rate (cases as % of population)", y = "Frequency",
title = "Regional COVID-19 rates: week ending 2021-12-04") +
theme_minimal() +
theme(panel.grid.major.y = element_blank())
In this instance, it is the tidyverse code that is the more elaborate. This is partly because there is more customisation of it to mimic the base R plot. However, it is also because it is using the package ggplot2 to produce the histogram. We return to ggplot2 more in later sessions. For now it is sufficient to scan the code and observe how it is ‘layering up’ the various components of the graphic, which those components separated by the + in the lines of code.
The use of the + notation in ggplot2 operates a little like a pipe in that the outcome of one operation is handed on to the next to modify the graphic being produced. It doesn’t use the pipe because the package’s origins are somewhat older but just think of the + as layering-up – adding to – the graphic.
I prefer the ggplot2 to the hist() graphics plot but that may be a matter of personal taste. However, ggplot2 can do ‘clever things’ with the visualisation, a hint of which is shown below.
df2 |>
ggplot(aes(x = rate)) +
geom_histogram(colour = "black", fill = "grey", binwidth = 0.05,
center = -0.025) +
geom_rug(aes(colour = regionName), size = 2) +
labs(x = "rate (cases as % of population)", y = "Frequency",
title = "Regional COVID-19 rates: week ending 2021-12-04") +
scale_colour_discrete(name = "Region") +
theme_minimal() +
theme(panel.grid.major.y = element_blank()) 
Please don’t form that impression that ggplot2 is hard-wired to tidverse and base R to the base graphics. In practice, they are interchangeable.
Here is an example of using ggplot2 after a sequence of base R commands.
df1 <- read.csv("covid.csv")
df1 <- df1[, c("regionName", "X2021.12.04", "All.Ages")]
names(df1)[c(2,3)] <- c("cases", "population")
df1$rate <- round(df1$cases / df1$population * 100, 3)
ggplot(df1, aes(x = rate, y = regionName)) +
geom_boxplot() +
labs(x = "rate (cases as % of population)",
y = "region",
title = "Regional COVID-19 rates: week ending 2021-12-04") +
theme_minimal()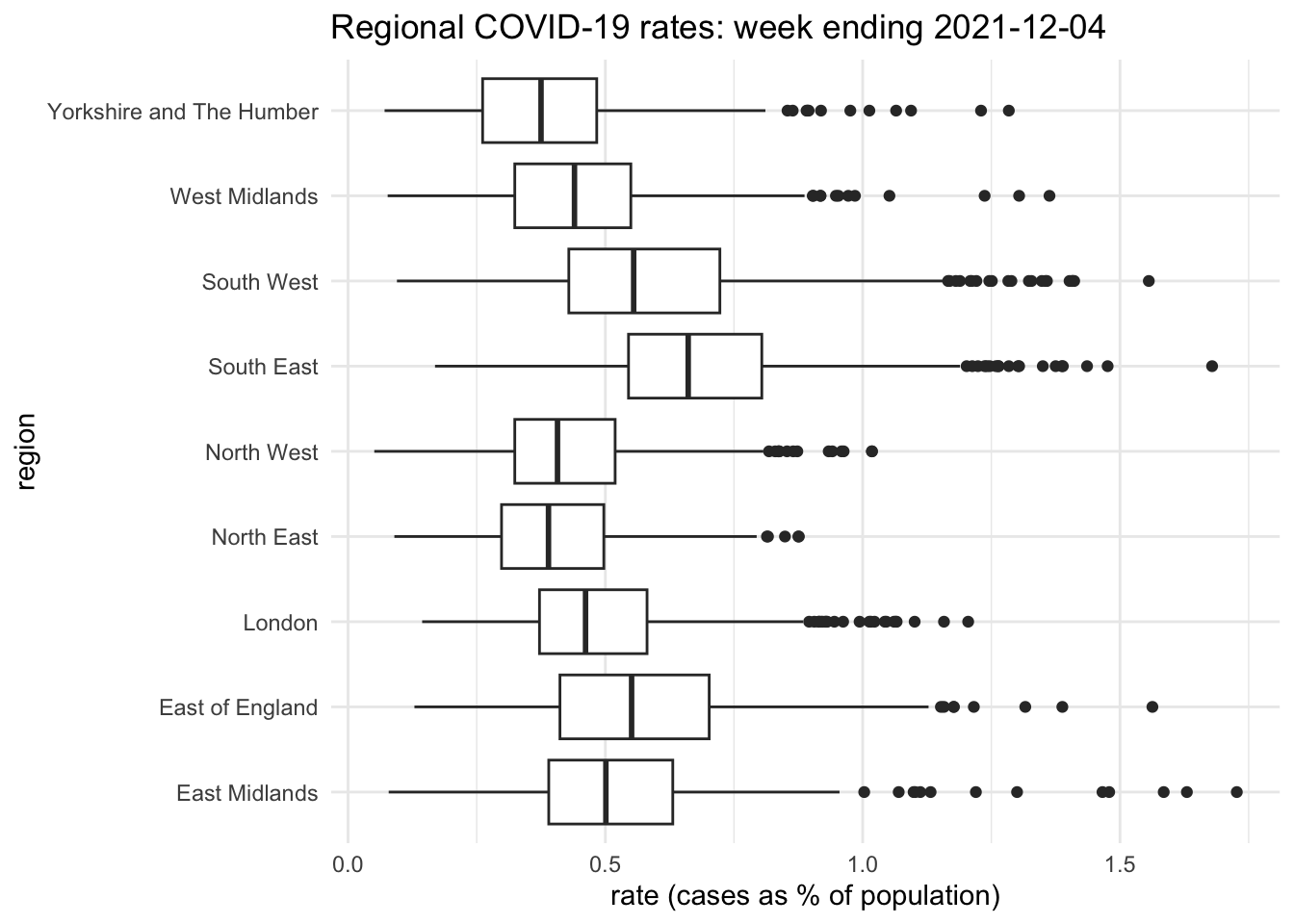
And here is an example of using the base R graphic boxplot() after a chain of tidyverse commands.
read_csv("covid.csv") |>
select(regionName, `2021-12-04`, `All Ages`) |>
rename(cases = `2021-12-04`, population = `All Ages`) |>
mutate(rate = round(cases / population * 100, 3)) -> df2
par(mai=c(0.8,2,0.5,0.5), bty = "n", pch = 20) # See text below
boxplot(df2$rate ~ df2$regionName, horizontal = TRUE,
whisklty = "solid", staplelty = 0,
col = "white", las = 1, cex = 0.9, cex.axis = 0.75,
xlab = "rate (cases as % of population)", ylab="",
main = "Regional COVID-19 rates: week ending 2021-12-04")
title(ylab = "region", line = 6)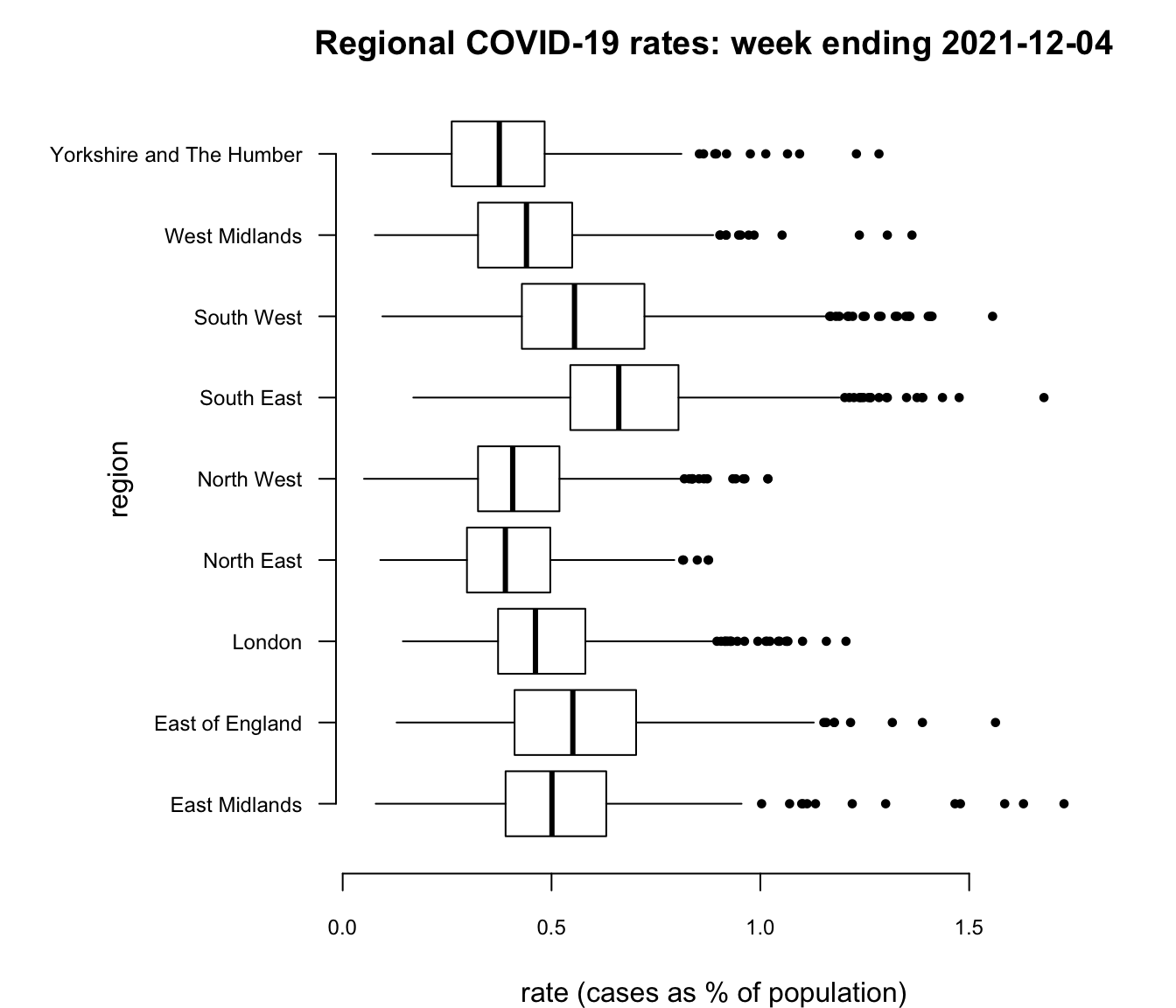
I would argue that, in this instance, the base R graphic is as nice as the ggplot2 one but it took more customisation to get it that way and I had to go digging around in the help files, ?boxplot, ?bxp and ?par to find what I needed, which included changing the graphic’s margins (par(mai=...))), moving and changing the size of the text on the vertical axis (the argument cex.axis and the use of the title function), changing the appearance of the ‘whiskers’ (whisklty = "solid" and staplelty = 0), and so forth. Still, it does demonstrate that you can have a lot of control over what is produced, if you have the patience and tenacity to do so.
Having provided a very small taste of tidyverse and how it differs from base R, we might ask, “which is better?” However, the question is misguided: it is a little like deciding to go to South America and asking whether Spanish or Portuguese is the better language to use. It depends, of course, on what you intend to do and where you intend to travel.
I use both base R and tidyverse packages in my work, sometimes drifting between the two in rather haphazard ways. If I can get what I want to work then I am happy. Outcomes worry me more than means so, although I use tidyverse a lot, I am not always as tidy as it would want me to be!

There is much more to tidyverse than has been covered here. See here for further information about it and its core packages.
A full introduction to using tidyverse for Data Science is provided by the book R for Data Science (2nd edition) by Hadley Wickham and Garrett Grolemund. There is a free online version.